Research Purpose
Unlabeled speech data와 적은 Labeled speech data로 충분히 음성인식기를
개발하기 위해 Self-supervised Learning 알고리즘 활용자연어 처리에서 Transformer로 비약적인 발전을 이룬 것처럼
음성 인식 분야에서도 Transformer로 뛰어난 발전을 이루기 위해 제안
Abstract
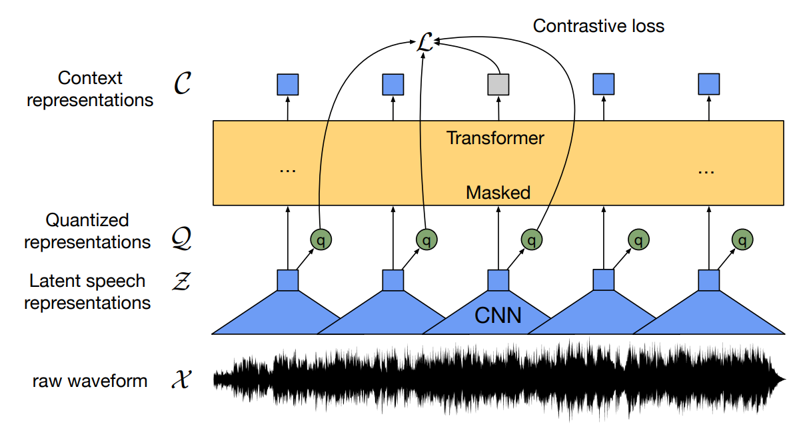
Architecture

- Unlabeled speech data로 pre-training 이후,
Labeled speech data로 fine-tuning을 진행하는 구성 (wav2vec)

Quantization Module로 Latent speech representation을 discrete 형태로 생성 (VQ)
(But. wav2vec 2.0은 loss 계산에서만 quantized representation을 활용 & Context는 기본 Z 활용)Transformer의 encoder로 context C를 생성하고, BERT의 MLM*과 유사한 아키텍처 (VQ)
* MLM: Masked Language Modeling
Contrastive Loss를 활용한 Contrastive Learning
Gumbel-softmax에서 sampling 후, Discrete speech unit으로
학습이 가능하도록 설정, Contrastive Learning에서 자동으로 학습 진행최종 Loss는 Contrastive Loss와 Diversity Loss 활용 (New)
이전 연구(vq-wav2vec)과 다르게 quantization에 이어 contextualized
representations를 진행한 것과 다르게, 두 과정을 end-to-end로 진행 (New)
Result

- Large 기준 LibriVox(LV-60K)의 Unlabeled data set의 모든 데이터로 pre-training 후
Libri-speech 960h Labeled data set으로 학습했을 때
Clean(5.4h)의 경우 1.8WER* 달성, other(5.1h)의 경우 3.3WER 달성
* WER(Word error rate): 단순 단어 오류 수치로 음성인식에서 사용하는 기본 성능 측정 단위

- Libri-light의 약 10분 Labeled data set로 학습했을 때, 각각 4.8/8.2 WER 달성
- 제한된 개수의 labeled data로 이전 최신 알고리즘*과 비교할 수준의 충분한 가능성을 보여주는 것이 핵심
Model Architecture(Pre-training)
Summary

Feature Encoder – Quantization Module

Feature Encoder (CNN, Latent)

- Feature encoder는 400개 sample
또는 25ms audio의 input을 가짐 - Raw waveform을 20ms stride로 49hz output을
\(Z_{0}, Z_{…}, Z_{T}\) 의 sequence로 생성해 차원의 수를 축소
1) Raw waveform → Normalized
2) 7 blocks CNN with 512 channels (single-dim)
Strides (5,2,2,2,2,2,2), Kernel width (10,3,3,3,3,2,2)
Generate codebook
- Quantization 과정 이전에 쌍을 이루는 codebook 생성
1) Codebook(groups)을 sampling하여 codewords V 생성
2) 모든 codebook에 V=320(Z 개수), G=2(그룹의 수)를 부여함
3) 이론상 \(V^g\) = 320 x 320 = 102400 speech unit 생성
Quantization Module

- Quantized Q를 생성하기 위해 Continuous를
Discrete으로 변환하기 위한 과정 - Discrete 상태에서 미분, 적분이 불가능
Gumbel-softmax를 사용해 자유롭게 학습 가능
1) Latent Speech representations Z와 Quantization의 합성곱
2) 결과물인 Logits에 Gumbel-softmax 수행
3) One-hot vectors 추출
Gumbel-Softmax

- 생성한 codebook에서 가장 알맞은 codeword 선택
1) Z가 Quantization Matrix와 합성곱 → logits 생성
2) Gumbel을 각 logits에 대해 적용하여 확률 추출
3) Argmax를 통해 one-hot vector 생성
4) 결과 vector e와 ont-hot과 연결되어
최종 Quantized tartgets Q 생성

- 수식
\(l_{g, k}\) – Z로 생성한 logits
τ – temperature(분포 조절 파라미터)
\(n_{k} – -log〖(-log(u_{k} ))〗\) | \(u_{k}\) - sampled
Transformer(Context Network) & Contrastive Loss

Masking

1) Latent Z의 공간에 모든 time-step 대상
2) 임의로 선택된 time-step를 시작 인덱스로 설정
3) 선택된 각 인덱스 i부터 M시간에 걸쳐서 Masking
- 시작 인덱스가 중복되는 경우 상관 없이
time-step에 따라 M시간(10개) Masking
Transformers (Context Network)

1) Latent speech representation Z에
feature projection 수행 (\(Z^l\))
2) 위치 정보를 갖기 위해 Positional Embedding으로
\(Z^l\) 에 position vector추가 (self-attention을 위해)
3) 위 Input을 통해 Transformer encoder을 지나
Context representations C를 output
Training
Objective – Contrastive Loss + Diversity Loss

- 기존에 Contrastive loss만 사용한 것과 다르게 Diversity loss와 함께 loss 합으로 진행
Contrastive Loss

- Contrastive Loss를 활용한 Contrastive Learning

\(L_{m}\)함수는 기본적으로 softmax와 유사
context \(C_{t}\) 와 Quantized \(q_{t}\)사이에 sim 적용마지막으로 더 쉬운 최적화를 위해 –log로 마무리
| \(c_{t}\), \(q_{t}\) – Positive | \(c_{t}\),q~ – Negative |
\(sim – cosine similarity\) | exp(a) – \(e^a\)
k – 현재까지의 평균 τ
Diversity Loss

- 생성한 codebook에서 V항목이 동일하게 자주 사용하도록 유도하기 위해 diversity loss 활용
- Diversity loss를 사용하지 않아 codeword 일부만 선택하게 될 경우 잠재성을 잃음
- Entropy 기반으로 계산 진행 (데이터 분포가 균일할 때 최대값을 추정) → \(L_{d}\) 최소화되는 것이 목표
Model Architecture(Fine-tuning)
Summary

Fine-tuning은 이전의 논문의 형식과 비슷한 구조
Pre-training과 비슷한 구조지만, Quantization 사용 X
Quantization 대신 랜덤 linear projection을
Context representation에 추가하여 학습에 활용CTC loss를 통해 optimize 진행
SpecArgument로 time-step 마다 Masking하여 overfitting을 방지하여, 적은 label을 가진 데이터셋에 더 낮은 에러율을 기록할 수 있도록 학습 (Regularization)
Datasets
Libri-speech

- LibriVox의 결과로, 음성 인식 연구에 가장 널리 사용되는 대규모 영어 음성 데이터
- 한 번에 긴 발화시간을 갖는 약 1000시간의 오디오북 데이터 (16kHz Sampling)
- Data argument로 다양한 버전의 종류가 파생되어 나옴 clean or other
Results
High-Resource Labeled Data Evaluation

- LibriVox(LV-60K)의 Unlabeled data set의 모든 데이터로 pre-training 후
Libri-speech 960h Labeled data set으로 fine-tuning 했을 때 (Large 기준)
Clean(5.4h) – 1.8WER* 달성, other(5.1h) – 3.3WER 달성
Low-Resource Labeled Data Evaluation

- LibriVox(LV-60K)의 Unlabeled data set의
모든 데이터로 pre-training 이후
1) 10min Labeled data set으로 fine-tuning
Large 기준 4.8/8.2 WER 결과 확인
2) 1h Labeled data set으로 fine-tuning
Large 기준 2.9/5.8 WER 결과 확인
3) 10h Labeled data set으로 fine-tuning
Large 기준 2.6/4.9 WER 결과 확인
4) 100h Labeled data set으로 fine-tuning
Large 기준 2.0/4.0 WER 결과 확인
Phoneme Recognition on TIMIT

음소 인식을 위해 Unlabeled Libri-speech training data set의 모든 데이터로 pre-training 후
Phoneme에 대한 5시간 Labeled TIMIT training data로 fine-tuning 하여 학습 진행이전 모델(vq-wav2vec)에 비해 각각 2.2/3.3 PER*이 줄어 23%/29%의 error 감소
Conclusion
Presented
1) Latent representations을 Masking하여 학습에 적용
2) Quantized speech representation으로 Contrastive task 수행
Achievement
1) Self-supervised learning으로 할 수 있는 최대한의 잠재력을 Unlabeled speech data로 보임
2) 평균 12.5초의 48개 녹음, 10분의 적은 양의 Labeled speech data로 4.8/8.2 WER 달성
3) 특히 Noisy speech에서 새롭게 가장 높은 성능을 기록하는 기술을 선보임
4) Seq2seq 또는 word piece로 전환하여 더 큰 성능 향상의 기대 가능