들어가면서
Tacotron1이 오픈소스로 공개되면서 많은 사람들이 이를 활용한 서비스를 많이 개발했다.
충분히 좋은 성능으로 자연스러웠지만, 구글은 더 완벽한 성능을 위한 개발을 끊임없이 진행했다.
2018년 구글은 변경된 구조의 Tacotron과 Vocoder를 Griffin-Lim 대신 Wavenet을 적용한 모델, Tacotron2를 발표했다.
2021년 기준 4년이 지난 지금도, 아래 표에 보다시피 최상위권 수준의 성능을 보이는 모델이다.

Introduction
딥러닝 기술 탄생 이전의 음성합성 기술엔 아쉬움이 많았다.
이미 저장된 파형의 자잘한 단위를 연결하는 방식이었기에 이질감이 상당했다.
Vocoder의 등장과 함께 통계를 활용하여 음성이 급격하게 부드러워지기 시작했다.
그러면서 음성합성에 있던 대부분의 문제가 해결되었다.
당시, 가장 유명한 vocoder는 wavenet으로 실제 인간의 음성과 비슷한 수준으로 생성할 수 있다.
성능이 좋지만 generate에 많은 시간이 소요된다는 점이 단점인데 이는 wavenet 게시글에서 자세히 알 수 있다.
Tacotron2

Tacotron2는 2가지 Task를 가지고 있다.
첫 번째는 텍스트를 input으로 받아, Mel-spectrogram을 생성하는 것 (Tacotron2 메인)
두 번째는 Mel-sepctrogram으로 음성을 생성하는 것 (wavenet 등 vocoder)이다.
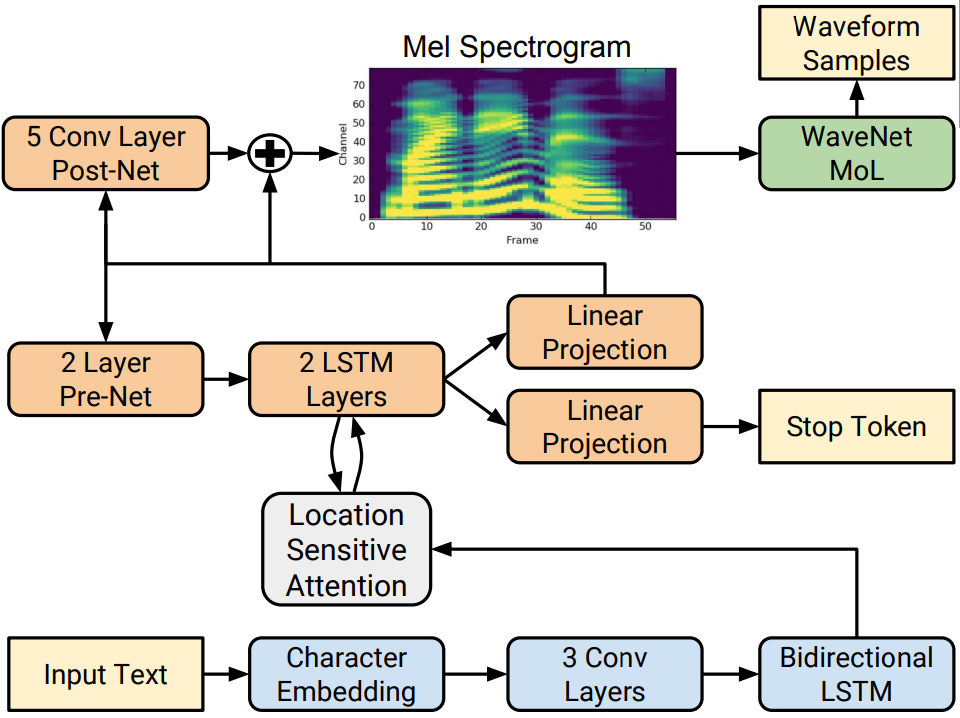
Tacotron2 구조
위에서 언급했듯이, Tacotron2의 Input은 char이며, output은 mel-spectrogram이다.
진행 순서는 크게 Preprocessing → Encoder → Attention → Decoder 라고 보면 된다.
요약하면 각 기능은 다음과 같다.
Encoder : input의 char를 일련의 길이의 히든 벡터(feature)로 변환
Attention : Encoder에서 생성된 히든 벡터를 시간 순서에 따라 정보를 추출하여 decoder에 전달
Decoder : Attention에서 얻은 정보를 이용해 mel-spectrogram을 생성
자세한 내용은 다음 카테고리에서 자세히 다루겠다.
Preprocessing

모델 학습을 위해 input과 output이 하나로 묶인 데이터 필요하다. (텍스트와 음성)
Input의 경우, 텍스트는 char 형식으로 변경하고, 음성은 mel-spectrogram으로 변환한다.
하나하나 알파벳(자음, 모음)으로 나누고 one-hot 인코딩을 통해, ‘안녕 반가워’ 같은 char 시퀀스를 정수열로 변경하고 모델의 input으로 사용한다.

한글 : 초성(19개), 중성(21개), 종성(27개)
Output의 경우, 음성 데이터를 spectrogram을 만들기 위해 Fourier transform 사용한다.
시간에 따른 변화를 반영할 수 없어 특정 길이로 잘라 fourier transform을 하는 STFT로 spectrogram 생성한다.

이후 spectrogram을 mel-filter bank 비선형 함수를 적용해 low frequency 영역 확대한다.
→ 사람 귀는 고주파보다 저주파에 민감하고, 고주파 영역이 작기 때문에 더 사람 친화적이다. 이후 log scaling을 통해 mel-spectrogram 생성 후 label로 활용하게 된다.
(STFT: Short-Term Fourier transform)
Encoder
Char 단위의 ont-hot vector를 encoded feature로 변환한다.

구성은 순서대로 char embedding → 3 x 1D Convolution Layer → Bidirection LSTM이다.
- Input으로 one-hot vector가 삽입되면, embedding matrix로 512차원 vector로 변환된다.
이후 vector는 3개의 1D conv-layer를 지나 bi-LSTM에서 encoded feature로 변환된다. - bi-LSTM은 zoneout을 적용했으며, 구조는 다음과 같다.

- (zoneout의 구조)
현재 state에 이전 state를 뺀 것에 dropout 적용
이 벡터를 이전 state에 더해 새로운 state 생성 (cell state와 hidden state 모두 적용)
→ dropout보다 이렇게 한 차례 마스킹을 하는 것이 RNN에 더 효과적이라고 발표
Attention

Encoder의 bi-LSTM에서 생성된 encoded feature를 decoder의 LSTM에서 활용할 정보를 가져오는 것으로, Attention은 반복을 진행할 때마다 encoder에서 내용을 추출하여 decoder에 전달한다.
핵심은 encoder로부터 어떤 정보를 가져올지 alignment(가지런히) 하는 과정을 의미한다.
Location Sensitive Attention
이전 state(시점)에 생성된 attention alignment를 이용해, 다음 state의 attention alignment를 구할 때 추가로 고려한 형태이다.
기존 attention과의 차이점은 score 계산 전에 이전 state가 포함된다.

위 식에서 Uf가 추가되며, 기존 socre 계산식과 차이가 발생했는데, 여기서 f는 이전 state의 conv에서 얻은 feature다.Score를 계산할 때 일반적인 softmax를 사용하지 않고, smoothing을 사용한다.

Decoder
Attention에서 얻은 alignment feature와 이전 state에서 생성된, mel-spectrogram을 이용하여 다음 시점의 mel-spectrogram을 생성한다.
모델 구성
Pre-Net → Decoder LSTM → Projection Layer → Post-Net
Pre-Net은 Fully Connected(256) 2개 + Relu 이전 state의 mel-spectrogram이 input으로 삽입되어 중요 정보 거름망 역할
Decoder LSTM은 uni-directional LSTM(1024) 2개로 구성 Pre-Net에서 생성된 vector와 이전 state의 context(맥락) vector를 합치고, Decoder LSTM을 통과하여 Attention과 Pre-Net 정보로 현재 state의 정보를 생성
그림을 보면 양갈래로 나뉘어 진행되는데, 하나는 종료 조건 확률 계산 경로, 하나는 mel-spectrogram을 생성 경로
종료 조건의 경우, state마다 생성된 vector를 FC를 지나 sigmoid를 취하여 0~1 사이 값으로 확률 변환, 만약 threshold를 넘을 경우 예측 단계에서 생성 종료
Mel-spectrogram 생성의 경우, state마다 생성된 vector와 attention의 context vector를 합치고 FC를 지남, 생성된 mel-vector로 예측에서 decoder의 다음 state의 input으로 활용됨
Post-Net은 5개 1D Conv Layer인데, Conv는 512개 filter와 5*1 kernel size를 가짐 이전의 mel-vector가 Post-Net을 지나고 다시 mel-vector 구조로 유지되는 Residual Connection임. 즉, mel-vector를 보정하는 역할을 하며, 최종적으로 mel-spectrogram의 품질을 높이는 역할을 함
Wavnet
Tacotron2의 2번째 Task의 단계로, Mel-spectrogram을 생성하는 단계이다.
자세한 내용은 아래 주소에 정리되어 있다.
https://hwrg.github.io/posts/딥러닝-기반의-음성합성-Vocoder-Wavenet/