들어가면서

어느 순간 기계 목소리가 자연스러워졌음을 느낀 적 있을 것이다.
내 경우엔 느긋한 구글 Assistant의 목소리 때문인지 체감을 못했는데,
어찌되든 갑자기 부드럽게 음성을 제작할 수 있게 된 것엔 다 이유가 있었다.
대표적으로 Tacotron이 전 세계의 모든 음성 합성 기술력이 대폭 향상되는 데에 많은 기여를 했다.
드디어 신경망을 음성 합성에 자유롭게 활용하는 시대가 온 것이다.
구글에서 발표한 이 대단한 음성합성 모델에 대해 알아보고자 한다.
Tacotron의 역할
Tacotron은 제목에서 언급했듯이 음성을 합성하기 위해 고안된 모델이다.

우리가 구글 번역기를 사용할 때, 번역이 작동하는 알고리즘은 이전의 Text(나는)에서 이후의 Text(공부한다)를 생성하는 Sequence to Sequence 기술을 활용한다.
Sequence to Sequence의 구조는 다음과 같다.

영어 text를 input으로 넣으면, 이 text가 벡터화 되어 저장되고, 이를 바탕으로 Decoder에서 목표하는 Text에 대한 처리를 거친 후 프랑스어로 번역되어 output이 나온다.
마찬가지로 Tacotron에서도 이 Seq2Seq을 활용하는데, 자세한 내용은 뒤에서 다룬다.
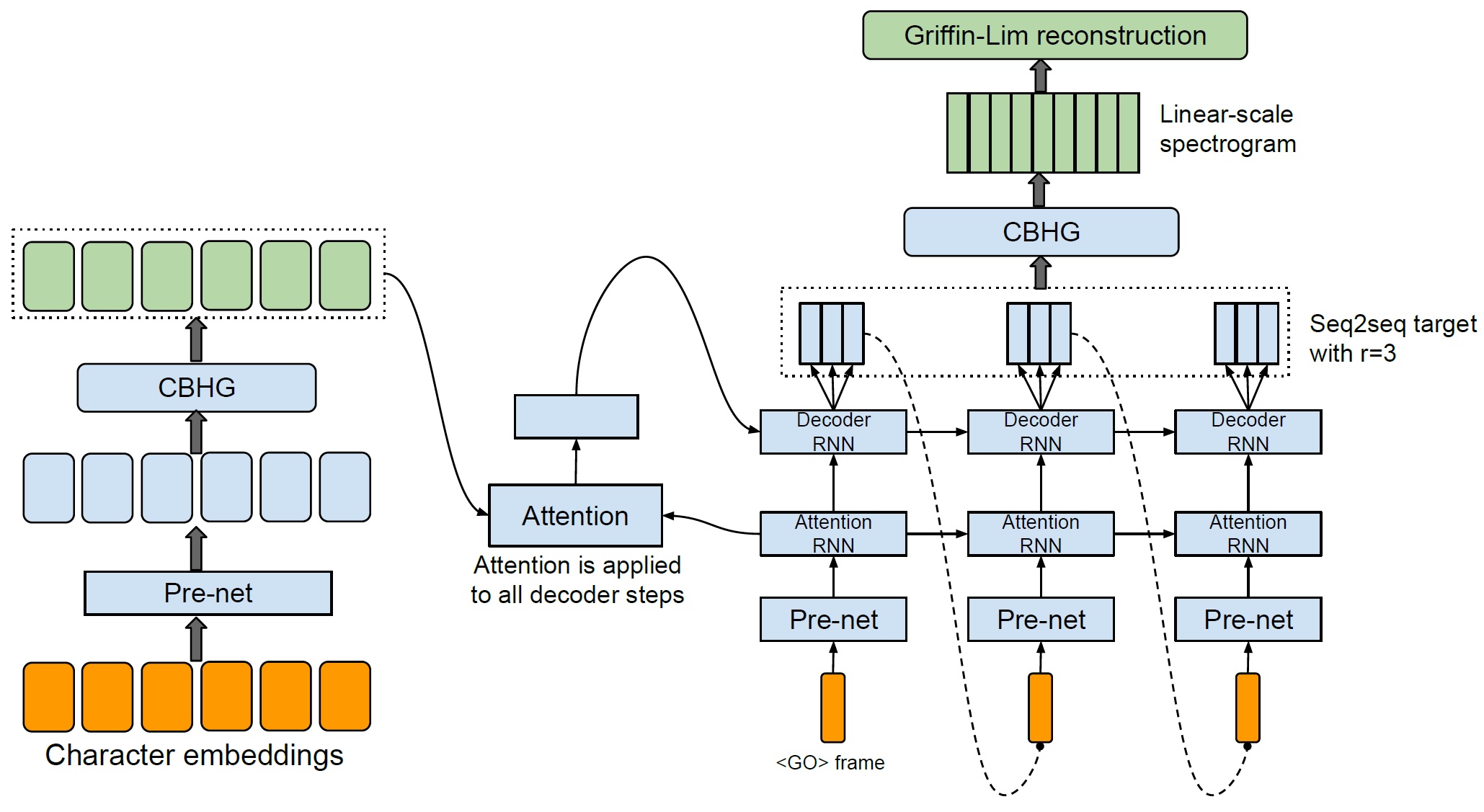
Tacotron 구조

게시글 최상단에도 첨부한 Tacotron의 전체 알고리즘 구조다.
크게 3구간으로 나뉜다. 먼저 input으로 들어온 text를 Character Embeddings을 진행한다. 이후 Encoding이 진행되고, Attention을 거쳐 처리된 내용이 Decoder의 RNN에 활용되어 최종적으로 Mel-Spectrogram을 생성한다.
그리고 Mel-spectrogram이 후처리를 위한 Post CBHG를 지나 Linear-Spectrogram이 생성되고 최종적으로 Vocoder에 이를 넘긴다.
그리고 Vocoder에서 Spectrogram을 갖고 음성으로 생성하면 하나의 음성 합성이 완성된다.
Encoder
인코더는 input 데이터를 Text Embedding을 하여 Pre-net과 CBHG를 거쳐 Sequences를 얻는 과정을 거친다.

순서는 Text Input → Pre-net → CBHG → Output(Vector)이며,
Pre-Net의 경우 FC(Dense) – ReLU – Dropout – FC – ReLU – Dropout 으로 이루어져있으며,
CBHG의 경우 Conv1D bank – Max pooling – Conv1D projections – Highway net – GRU(Bidirectional RNN) 으로 이루어져 있다.
각 레이어는 구글링하여 자세한 내용을 확인할 수 있으며, 추후에 블로그에 간단히 포스팅할 예정이다.
CBHG

CBHG를 사용하는 이유는, highway network를 사용함으로써 character 단위를 더 효율적으로 표현할 수 있게 된다.
최종적으로 highway 4번에 걸쳐 나온 vector가 attention에 사용될 query가 된다.

Decoder
Decoder에서는 Text에 대한 vector가 순환 신경망(Attention RNN, Decoder RNN)을 거쳐 Mel-spectrogram을 얻는 과정을 진행한다.
과정은 input(GO frame) → Pre-net → Attention RNN → Decoder RNN → Mel spectrogram 이다.

정리하자면, 가장 처음 비어있는
지속적으로 반복하여 얻은 Mel-Sepctrogram을 음성 합성의 재료가 된다.
Attention

기존에 Decoder RNN에서 필요한 context vector를 생성할 때 압축하는 과정에서 정보 손실이 발생했다.
또한 긴 문장(Long-term Dependency)의 경우 제대로 Decoder의 output 시퀀스가 생성되지 않는 것을 막고자 이를 묶어주는 역할을 위해 고안되었다.
Attention은 Encoder에서 생성된 output과 Decoder의 Attention RNN에서 생성된 output을 input으로 한다.
그리고 각 time-step마다 확률에 따라 align을 결정하여 context vector를 생성한다.
생성된 context vector는 Attention RNN의 output과 함께 Decoder RNN에 input으로 넣는 역할을 한다.
Post-Processing net
음성을 합성하기 위한 Linear-Spectrogram을 한 번에 만들어낼 수 있지만 Tacotron에서는 그러지 않았다.
그 이유는 Decoder에서 바로 Linear-Spectrogram으로 만들 경우, 상대적으로 harmonic이 적어서 부자연스럽기 때문이다.

위 사진에서 y축 DFT bin에서 하단 부를 보면 물결 모양이 (b)에서 섬세하고 많은 것을 확인할 수 있다.
그렇기 때문에 더 자연스러운 목소리의 spectrogram을 제작하기 위해 이런 방식을 채택한 것이다.
Vocoder(Griffin-Lim)
Tacotron은 만들어진 spectrogram을 더 자연스럽게 만들어내는 모델(Vocoder)로 Griffin-Lim을 선정했다.
Tacotron 논문이 세상에 나온지 거의 4년이 되어가는 상황에서 수많은 vocoder들이 탄생하고 있으며, 그 중 학계에 의미있게 알려진 Wavenet, Waveglow, MelGAN 등 여러가지 발표되었다.
안정적이고 더 성능이 좋은 모델이 출시되었기 때문에 Griffin-Lim은 구조만 확인하고 넘어가고자 한다.

Griffin-Lim은 딥러닝을 사용하는 것이 아닌 전통적인 Fourier Transform을 이용하는 방법으로,
STFT와 Inverse STFT를 반복하면서 spectrogram의 Magnitude에 대응하는 phase를 예측하는 방식이다.
위 과정을 통해 Tacotron에서 만든 Mel-Spectrogram을 오디오(wav) 파일로 변환한다.