Abstract
- SV2TTS로도 불리는 본 논문은 Speaker verification을 Multi-Speaker에 활용한 TTS 모델이다. 또한 학습되지 않은 화자의 음성을 몇 초만의 오디오로 비슷하게 표현해낼 수 있는 voice cloning도 제안하고 있다.
- 이 모델은 기존의 2개 학습 과정을 수행하는 것과 다르게, 3개 독립적인 학습으로 구성되어 있다.
- 약 15분 분량의 음성 데이터를 가진 18000명의 화자는 transcript 없이 학습하여 화자 검증 작업(d-vector)을 수행한다. 학습된 Speaker Encoder는 몇 초만의 음성 데이터로 fixed-dimension 임베딩 벡터를 생성하게 된다.
- Speaker Embedding 레이어를 추가한 Multi-Speaker Text-to-spectrogram을 수행하는 Acoustic 모델로 Tacotron2를 활용한다.
- Spectrogram-to-Waveform으로 변환하는 Autoregressive Vocoder 모델로 Wavenet을 활용한다.
- TTS 모델의 일반화 성능을 최대한 높이기 위해 많고 다양한 화자 데이터셋으로 Speaker Encoder를 학습한다. 그리고 학습한 데이터를 무작위로 샘플링하여 Speaker Embedding 레이어를 통과해 새로운 화자(speaker)와 비슷한 음성으로 복제해 합성해낼 수 있다.
요약: 10초 수준의 새로운 목소리와 비슷하게 생성해내고자, 최대한 여러 사람들의 발화의 구조를 조합하여 비슷하게 생성해낸다.
Introduction
본 모델은 학습하지 않은 화자의 초 단위 데이터만으로도 자연스러운 음성을 생성하는 TTS 시스템이다. (초 단위 오디오로 학습 없이 생성 가능한 zero-shot)
- 자연스러운 음성을 위해 수십분의 데이터로 n천 명이 넘는 데이터가 존재해야 하는 단점이 존재하는데, 이 문제를 해결하기 위해 화자의 특징 공간을 찾아내는 Speaker Verification Embedding을 미리 학습하고, 이를 활용하여 더 적은 분량의 데이터에서 고품질 TTS 학습을 통해 화자 모델링을 수행한다.
- 논문에서는 1200명의 음성 데이터로 Acoustic Model과 Vocoder를 학습하고, 18000명의 데이터로 Speaker Encoder를 학습했다. 이정도 데이터만으로 새로운 화자와 비슷한 목소리를 생성해낼 수 있었다. 이게 가능한 이유는 Speaker Encoder가 화자를 판별하는 역할로, 화자의 특징 공간을 잘 잡아내어 합성 시 적용하기 때문이다.
- 기존의 Tacotron은 single speaker만 가능하며, Deep Voice3는 multi-speaker를 활용해도, unseen data를 합성하지 못한다. 이런 점에서 논문에서 제시하는 모델은 fixed size memory buffer를 사용하는 VoiceLoop 모델에 가깝다고 볼 수 있다.
- 그리고 Speaker Encoder는 ‘Neural voice cloning with a few samples’의 구조와 거의 유사하지만, Acoustic Model과 Speaker Encoder를 독립적으로 둔다. 또한 Speaker Encoder는 화자 정보만 있으면 학습이 가능하다는 점에서 다르다.
- 물론 zero-shot transfer를 위해 d-vector에서 사용한 것보다 수천 명 더 많은 스피커에 대한 학습이 필요하다.
Multi-Speaker Speech Synthesis
Speaker Verification을 위해 GE2E loss를 사용하는 D-vector를 활용했다.
Speaker Encoder
Speaker Encoder는 합성 모델에 타겟 화자로 발화가 가능하도록 만드는 것이다. Speaker Encoder의 일반화 목표는 타겟 화자의 짧은 목소리만으로도 식별할 수 있어야 한다.
Encoder는 랜덤하게 선택한 발화에서 log-mel spectrogram frame을 뽑아 d-vector(fixed-dimensional 임베딩 벡터)로 매핑한다.
학습 과정은 end-to-end speaker verification을 최적화하도록 학습하여 같은 speaker로부터의 임베딩끼리는 더 높은 cosine similarity를 갖게 하고, 다른 speaker끼리는 멀게 하는 방식으로 학습한다.
Input 40-channel의 log-mel spectrogram은 768 cell로 구성된 LSTM(256 dimension projection) 3개를 지난다. 그리고 최종 임베딩은 마지막 레이어에서 나온 output에 L2 normalize를 적용하여 생성된다.
Inference and zero-shot speaker adaptation
- Inference 과정에선 텍스트와 일치할 필요 없이 음성 오디오를 사용해 조절한다. 즉 Inference의 화자 특징은 waveform으로부터 추론되는데, 외부 화자에서 나온 오디오로 조절할 수 있다.
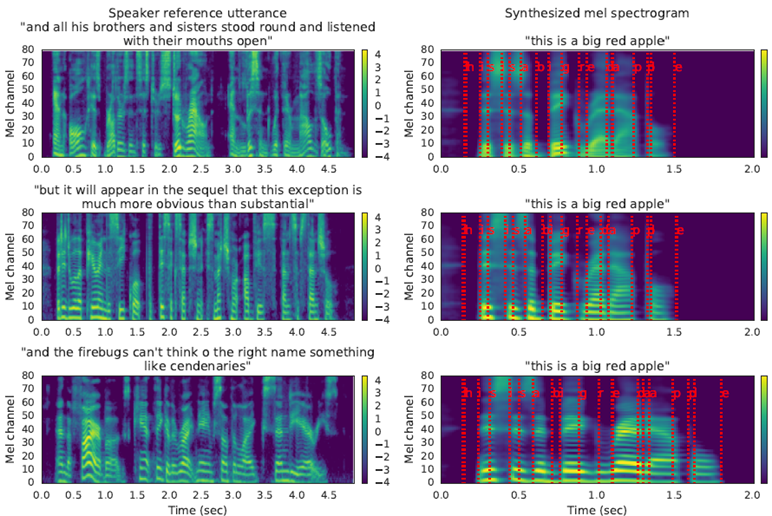
- Inference 과정은 아래 그림과 같이 10초 이하의 참고 문장을 통해 spectrogram을 재구성하여 화자 특성에 맞게 배치한다. 왼쪽 맨 아래 남성 발화의 spectrogram을 보면 길게 늘어진 부분이 있는데, 오른쪽 생성된 spectrogram을 보면 제대로 반영된 것을 확인할 수 있다.
Experiment
Dataset
Tacotron2와 Wavenet을 학습하기 위해 VCTK 데이터셋, 109명 화자 44시간 데이터와 LibriSpeech 데이터셋 1172명 화자 436시간 데이터를 사용했다.
데이터에 spectrogram 속 잡음을 제거하거나, 배경음을 줄이는 방식으로 전처리를 수행했다.
VCTK 데이터셋은 노이즈가 적어 데이터를 그대로 vocoder에 학습했으나, 노이즈가 많은 librispeech는 Tacotron으로 생성한 spectrogram이 성능이 좋은 것으로 확인되어 따로 waveform에 denoising을 수행하지 않는다.
Speaker Encoder는 1.8만명의 데이터로 평균 3.9초 분량의 3600만개 문장으로 학습했다. 이 데이터는 Tacotron2와 Wavenet에는 사용되지 않는다.
MOS로 평가를 수행하는데, 1~5로 선택하는데 0.5 단위로 등급을 매긴다. MOS 평가를 위해 Speech naturalness 와 Speaker similarity 두 가지 관점에 따라 평가한다.
Speech Naturalness
- 학습에 사용되지 않은 100개 문장을 생성하고, 2개의 세트로 나누어 평가를 수행했다. VCTK 데이터셋은 11명의 unseen / seen 화자로, LibriSpeech는 10개의 unseen / seen 화자로 평가했다.
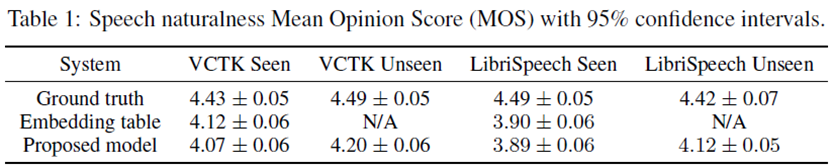
VCTK는 기본적으로 MOS 4.0을 넘었으며 LibriSpeech보다 약 0.2 높은 결과를 볼 수 있다. 이는 LibriSpeech가 transcript의 punctuation(구두점)이 부족해 자연스럽게 끊도록 학습이 안되는 점과 노이즈가 VCTK보다 많기 때문으로 판단한다.
들어보면 화자의 prosody가 reference의 prosody를 모방하는 경우가 있음을 확인하였고 이 덕분에 더 많은 운율을 가진 LibriSpeech에서 효과가 크다. 이런 경우는 화자 정체성을 분리하기 위해 추가적인 주의를 기울여야 함을 의미한다.
이는 합성 네트워크 내에서 운율 인코더를 통합하거나 [16, 24]에서와 같이 운율 인코더를 통합하거나 동일한 화자의 무작위로 쌍을 이루는 참조 및 대상 발화에 대한 교육을 통해 화자 ID를 운율과 분리하기 위해 추가 주의를 기울여야 함을 시사합니다.)
Speaker Similarity
- 동일한 화자로 만든 합성된 문장과 랜덤으로 선택된 Ground truth의 유사도를 비교한다. 평가자가 문법이나 상황 등을 고려하지 않고 오직 유사도에 집중해 평가하도록 지시했다.
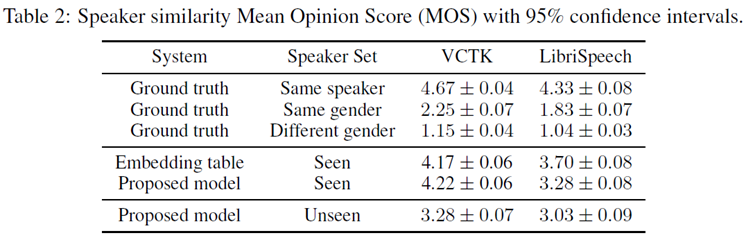
SV2TTS를 사용해 seen speaker set으로 합성한 결과를 비교했을 때 4.2로 높은 MOS를 보였지만, unseen speaker set으로 비교했을 때 3.28로 상대적으로 낮은 수치를 보였다. 3.28은 ‘적당히 유사’에 가까운 수치로, 정확한 성별과 pitch, formant 범위 특징을 잘 반영한다고 볼 수 있으나, prosody 관련 정보가 많이 손실되어 더 좋은 결과나 나오지 않았다고 판단한다.
VCTK의 경우 Speaker Encoder를 학습할 때 북미 발음으로만 학습하고, accent를 판단하는 법을 지정하지 않아 유사도 점수가 낮아진 것이라 판단한다. 억양이 다르면, 다른 화자의 것이라 판단하여 더 낮아지게 된다. (accent가 달라도 톤이나 목소리 특징이 유사하다고 하는 평가자도 존재)

- 일반화 능력을 평가하기 위해 각각 두 데이터셋으로 합성한 모델을 교차하여 다른 데이터셋에 테스트해 보았다. 두 데이터셋 모두 자연스러움은 4점 이상으로 높은 성능을 보였으나, LibriSpeech 모델이 훨씬 높은 유사도를 보인다. 즉, 100개 화자를 갖는 LibriSpeech 만으로는 고품질 speaker transfer에 충분하지 않음을 알 수 있다.
Speaker Verification
제한된 Speaker Verification 시스템에서 Unseen speaker에 대해 합성음과 실제 음성을 비교한다. 원래 1만명으로 학습했지만, 검증을 위해 11만명 화자 2800만개 데이터로 학습했다.
테스트를 위해 Acoustic과 Vocoder에서 사용하지 않은 unseen 화자 VCTK 11명, LibriSpeech 10명을 선택하여 테스트한다. 화자마다 100개의 테스트 음성을 생성하고 VCTK 21000번, LibriSpeech 23100번을 수행하여 테스트했다.
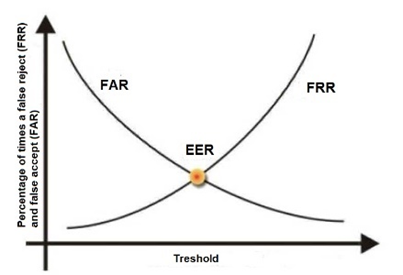
- 평가 방법은 EER(Equal Error Rate)로 FFR(False Reject Rate)과 FAR(False Acceptance Rate)이 같은 시점에서의 오류율을 의미한다. 1) FFR(False Reject Rate) – 시스템에 등록된 화자가 접근했는데, 해당 화자를 인식하지 못하고 인증을 거부하는 오류를 의미 → 허가된 화자가 오류로 인한 접근 거부 비율 2) FAR(False Acceptance Rate) – 시스템에 미등록된 화자가 접근했는데, 등록된 화자로 잘못 인식하여 허용하는 오류를 의미 → 미허가된 화자가 오류로 인한 접근 허용 비율
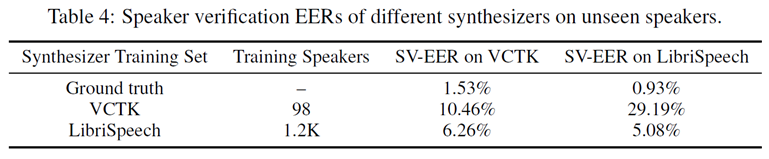
다양한 화자가 존재하는 LibriSpeech로 Speaker Encoder를 학습했을 때, 본인 데이터셋이나 더 적은 화자가 존재하는 VCTK 기준 5~6%로 Ground Truth와 크게 다르지 않은 수치를 보인다. 그러나 VCTK로 학습하고 LibriSpeech에 대한 EER은 29%로 상당히 높은 에러율을 보인다.
Ground Truth와 합성음을 비교하는 것이 어렵기에 확장된 LibriSpeech 데이터셋을 평가했으나, EER 2.86%로 타겟 화자에 가까운 경향이 있지만(cosine similarity > 0.6), 사실상 대부분 다른 음성에 가깝다(cosine similarity > 0.7). 그래서 타겟과 유사하긴 하지만 다른 화자와 헷갈릴 수 있기에 충분히 좋은 음성을 생성하지는 못한다고 알 수 있다.
Speaker Embedding space
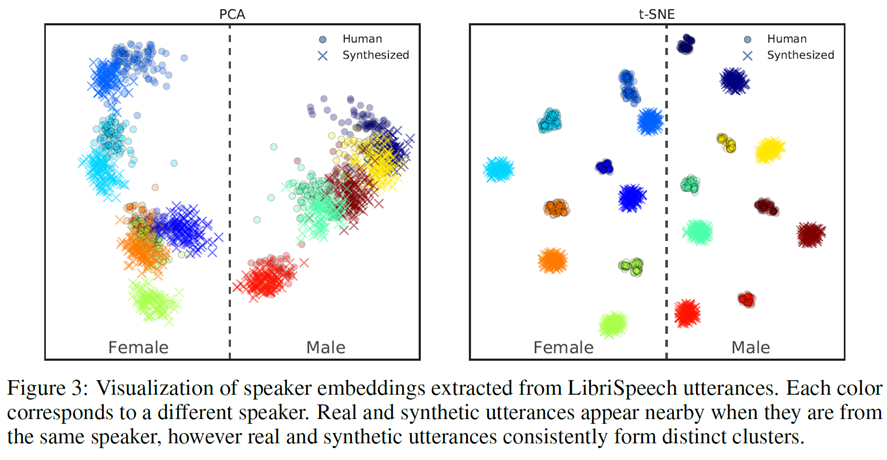
PCA로 나타냈을 때 합성음과 실제 음성이 비슷한 공간을 공유하여 유사함을 확인할 수 있으나, t-SNE로 나타냈을 때 확연히 합성음과 실제 음성이 가깝지만 별개의 클러스터를 형성하는 것을 확인할 수 있다.
클러스터 할 때 성별은 확실하게 PCA와 t-SNE 모두 잘 나눈 것을 확인할 수 있다. 즉, Speaker Encoder가 합리적으로 표현을 학습했음을 알 수 있다.
Number of speaker encoder training speakers
- 다양한 화자에 대한 일반화가 잘되는 이유가 speaker encoder으로 판단되기 때문에 학습된 representation의 퀄리티에 미치는지 확실하게 조사했다.
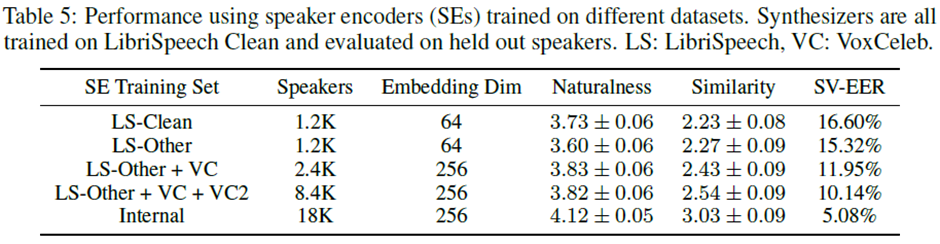
Table 5를 보면 확실히 품질 면에서는 Clean이 Other에 비해 품질은 좋지만 유사도가 미세하게 낮다. 그리고 LibriSpeech 기준으로 데이터를 추가할수록 정확도와 유사도 모두 상승하는 것을 알 수 있으며, 객관적인 지표인 SV-EER에서도 화자 수에 따라 더 낮은 에러율을 보인다.
이 결과를 통해 transcript가 존재하는 데이터를 요구하는 DeepVoice3의 Multi-speaker 다르게, 화자 정보만 존재하는 데이터로 speaker encoder 학습 후 synthesizer(tacotron2)에 적용하는 것이 비용적으로 유리하다는 것을 의미한다.
★ Fictitious speakers ★
- Speaker encoder를 활용하면 cloning의 기능을 수행할 수 있다. Speaker encoder를 bypassing하고 speaker embedding space의 특정 부분을 지정하여 Tacotron2로 합성하면 train과 test에서 학습하지 않은 목소리가 나온다.

Unseen 화자에 대해 합성을 수행하고, tacotron2와 speaker encoder 각각에 학습한 데이터 중, 랜덤으로 10개 뽑고 그중 가장 비슷한 화자와 비교했을 때 Table 6와 같은 결과를 보인다.
완전히 가상의 목소리지만 Naturalness MOS가 3.65으로 사람과 비슷한 수준이고, 가장 가까운 화자 목소리와 비교해 cosine similarity와 SV-EER을 측정하면 unseen data답게 높은 에러를 보여 학습한 목소리와 완전히 구별된다고 볼 수 있다.
Conclusion
본 논문은 Tacotron2과 별개로 독립적으로 speaker encoder를 transcript 없이 학습하여 seen data에서 좋은 성능을 보이고, 심지어 unseen data에 대해서도 좋은 성능으로 생성할 수 있도록 제안했다.
- 먼저 Tacotron2의 Multi-Speaker에 학습하는 화자의 수를 증가시킬수록, Speaker Encoder에서도 화자의 수를 늘리면 더 높은 품질을 얻어낼 수 있다는 것을 실험을 통해 증명해냈다.
- 즉, transcript가 있거나 고품질인 음성 데이터가 적은 경우에도 합리적으로 성능을 향상시킬 수 있음을 의미한다. 또한 독립적으로 두었기에 추가적인 triplet or contrastive loss가 필요하지 않아 모델 구조가 단순하다.
- 하지만, 몇 초의 reference 음성에 대한 부족한 유사도를 개선하려면 ‘Neural voice cloning with a few samples’이나 ‘Sample efficient adaptive text-to-speech’의 approach가 필요하다.
- 그리고 single speaker에 비해 화자 당 데이터가 부족하여 자연스러움이 부족하고, accent를 전달하는 데에도 제한 조건이 존재한다. 마지막으로 reference 음성에서 prosody를 음성과 완전히 분리할 수 없다는 점 또한 문제 또한 개선 할 요소다.