들어가면서
흥미롭고 핵심적인 모델이라 논문을 읽고 번역하며 작성해 봤지만, 난이도가 높아 내용이 중구난방임을 양해 바란다.
Flowtron은 제목의 내용과 같이 음성의 변형 및 스타일 변경을 자유롭게 제어하는 Autoregressive 생성 모델이다.
이는 Tacotron2를 개선한 모델로, Mel-spectrogram에서 합성을 진행한다.
Pitch(강도)와 톤, 운율, 억양 등을 고려하기 위해,
잠재적인 공간에 대한 invertible(가역)을 매핑하여 학습한다.
이 모델의 특징은 학습 중 보이지 않는 음성 변이를 제어하고, 샘플을 보간하며, 스타일 전달에 대한 결과를 제공한다.
Autoregressive Model
본격적으로 시작하기 전에, Autoregressive(자기 회귀)에 대해 간단히 알아보자.
자기 회귀는 시계열에서 현재 시점(yt)가 이전 시점((yt-1 ~ yt-p)에 선형적으로 의존하는 것이다.

위 식의 변수들이 의미하는 것은 다음과 같다.
𝜀𝑡 : normal distribute white noise (avg=0, dist=1) → N(0,1^2)
C : 상수, 절편을 의미
일반적으로 p차 자기 회귀 모델이라 하며, AR(p)라고 한다.
t(현재 시점)에 대한 변동은 t-1로부터 t-p까지 영향을 미친다.
일반적으로 p=1, 2까지 영향을 미치는데, 이를 AR(1), AR(2) 모델이라고 한다.
Introduction
일반적으로 음성 합성은 텍스트 입력에 따라 음성 생성의 공식화를 진행하여,
텍스트가 아닌 내용에 대한 정보를 반영하기 어렵다.
그래서 일반적으로 비텍스트의 경우 레이블이 따로 적용되지 않아 unsupervised learning을 진행한다.
Flowtron 모델의 경우, 목표는 학습 데이터에 패턴을 일치시키는 것이다.
유저가 데이터셋의 구조의 인사이트를 얻을 수 있도록 unsupervised learning을 공식화한다.
데이터가 일부 잠재 공간에 표현된 것이라 가정 후 모델이 표현을 학습하도록 한다.
잠재 공간을 조사하고 조작하여 유저가 생성 모델의 출력을 더 잘 제어하도록 한다.
이 approach가 이미지 생성에 사용되면서 이미지 간의 연결이 매끄러워졌고, 잠재 공간 부분 식별에 유용했다.
오디오에 적용하고, 많은 정보를 제거하고 유용한 것에 대한 가정으로 얻기 위해 임베딩에 포커싱한다.
2018년 발표된 emotional 음성 합성은 위 방식을 채택하여 오디오를 인코딩하는, Gaussian mix model에 Tacotron2를 추가하여 임베딩을 학습한 것이다.
이 논문은 가변 길이 임베딩은 텍스트와 화자와 연결성이 약해 고정 길이 임베딩에 집중한,
‘음향 및 음성을 제어하는 mel-spectrogram 합성을 위한 autoregressive 흐름 기반 생성 네트워크이다.
mel-spectorgram의 분포를 원형의 가우스로 매개변수화 된 잠재 z공간에 매핑하는 역함수를 학습 (이해 필요)
이 공식을 통해 z공간에서 해당 공간을 찾고 샘플링 하여, mel-space에서 나타나는 음성 특징을 포함하는 샘플을 생성할 수 있다.
이는 Tacotron보다 단순하지만 더 많은 음성 변화를 제공한다.
Flowtron은 autoregressive의 성질을 활용하여 기존 샘플의 증거를 조건으로 이후 분포를 샘플링하여, mel-spectrogram의 공간의 특정 영역에 접근할 수 있다.
이는 표현을 위한 발화와 관련된 z-space을 계산하여 더 풍부한 표현이 가능하다. 결국 구성요소 또는 이전 것들의 혼합을 선택하여 음성에 특징을 가진 샘플을 생성한다.
VAE와 GAN 기반 생성 모델도 쉽게 조작할 수 있는 잠재(latent) 사전을 제공하지만, flowtron에서는 품질과 최적화에 대해 추가 비용이 들지 않는다.
마지막으로 Flowtron이 추가적인 prenet 또는 postnet이 필요하지 않고, 데이터 가능성을 극대화하여 선명한 mel-spectrogram을 일반화하고 생성할 수 있다.
또한 훈련이 간단하고 안정적으로 되어 용이하다.
Related Work
텍스트 외 정보를 위해 접근 방식으로 수렴하고 일반화하기 위해 prenet을 추가 했다. 인공물을 줄이는데 더 나은 고주파수 포만트를 만들기 위해 postnet과 수정 loss 필요하다.
다른 방법은 비텍스트에 운율 또는 글로벌 스타일에 잠재 임베딩을 학습한다.
임베딩 뱅크 또는 운율의 잠재 임베딩 공간이 비텍스트(label X) 데이터를 학습 진행 위 사항들은 합성 전에 오디오 통계화 음향 표현을 임베딩에서 모두 결정해야 한다. (단점)
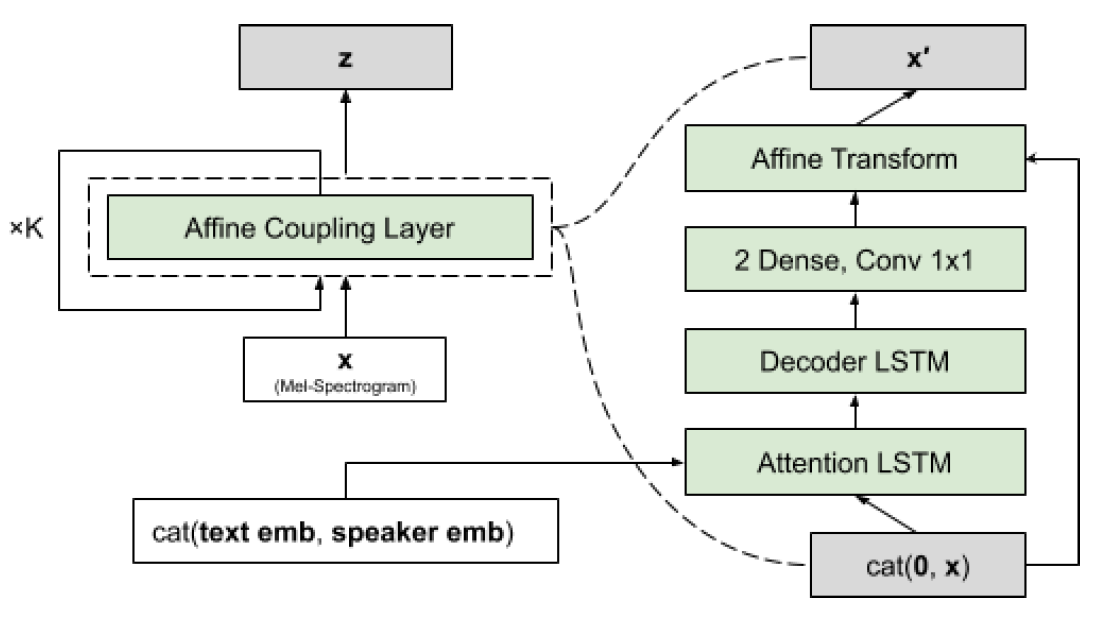
Flowtron Model
Flowtron은 이전의 Mel-spectrogram 프레임을 기반으로 현재 프레임을 생성하고, 그 프레임 p(x)의 sequence를 생성하는 autoregressive 생성 모델 [p(x) = πp(xt|x1:t-1)] 이다.
여기서 mel-spectrogram과 같은 차원 수를 가진 2개의 간단한 분포를 고려한, 평균이 0인 원형 가우스와, 매개 변수를 가진 고정 또는 학습이 가능한 원형 가우스 혼합한다.
이후 계속..