Abstract
기존에 제안된 Tacotron은 concatenative, statistical parametric보다 자연스러운 음성 합성이 가능했으나, Autoregressive 구조로 이루어져 있어 inference 과정이 상당히 느리다. 또한 불완전한(발음 무시 등) 모습을 자주 보이기도 했으며, 속도와 운율 제어에 한계가 존재했다. 
FastSpeech는 feed-forward 기반 Transformer 모델로 mel-spectrogram을 parallel하게 생성한다. 또한 Phoneme duration prediction을 가진 encoder-decoder의 구조의 teacher 모델에서 attention alignment 추출하고 FastSpeech에 적용한다. 이는 phoneme 시퀀스를 확장하고 target mel-spectrogram 시퀀스에 매치하여 병렬로 추출해내는 것이다.
FastSpeech는 Autoregressive 모델과 비슷한 성능을 보이면서도, 합성 속도를 크게 향상시키고 발음을 무시하거나 재발음하는 문제를 해결했다. Transformer TTS와 비교했을 때, mel-spectrogram만 생성했을 때 270배, Vocoder 포함 합성 속도는 38배 더 빠르다.
Introduction

이전 모델들의 문제점
1) Autoregressive 모델만이 아니라, CNN, Transformer TTS도 이미 생성된 mel-spectrogram을 조건으로 새로운 mel-spectrogram을 생성하고 일반적으로 mel-spectrogram program 길이가 수백~수천 개라 inference 속도가 느리다.
2) 합성된 음성이 견고하지 않아 Backpropagation 또는 autoregressive generate 과정에서 텍스트와 오디오 사이에 잘못된 alignment가 발생해 단어를 스킵, 반복하는 문제가 발생한다.
3) 텍스트와 오디오 사이에 alignment를 확실하게 하지 않고 하나씩 자동으로 생성한다. 따라서 speed와 prosody를 직접 제어할 수 없다.
FastSpeech는 NLP에서 제안된 self-attention 기반 feed-forward 모델 Transformer와 1D Convolution으로 구성된다.
이전 TTS 모델에서 문제된, mel-spectrogram 시퀀스와 phoneme 시퀀스 사이에 길이가 다른 문제를 해결하고자 Length Regulator를 사용해 phoneme 시퀀스를 up-sample하여 길이를 동일하게 맞추었다. 이때 Regulator는 phoneme duration predictor를 활용한다.
핵심 제안 항목
1) Autoregressive 모델의 자동 attention alignment와는 다르게, Phoneme Duration Predictor로 hard alignment를 수행하여 단어를 skip하거나 반복되는 비율을 현저히 줄인다.
2) Length Regulator로 목소리의 강약에 대한 속도를 phoneme duration을 쉽게 조절해 mel-spectrogram을 하거나, phoneme 사이에 break를 넣어 prosody를 조절할 수도 있다.
Model Architecture
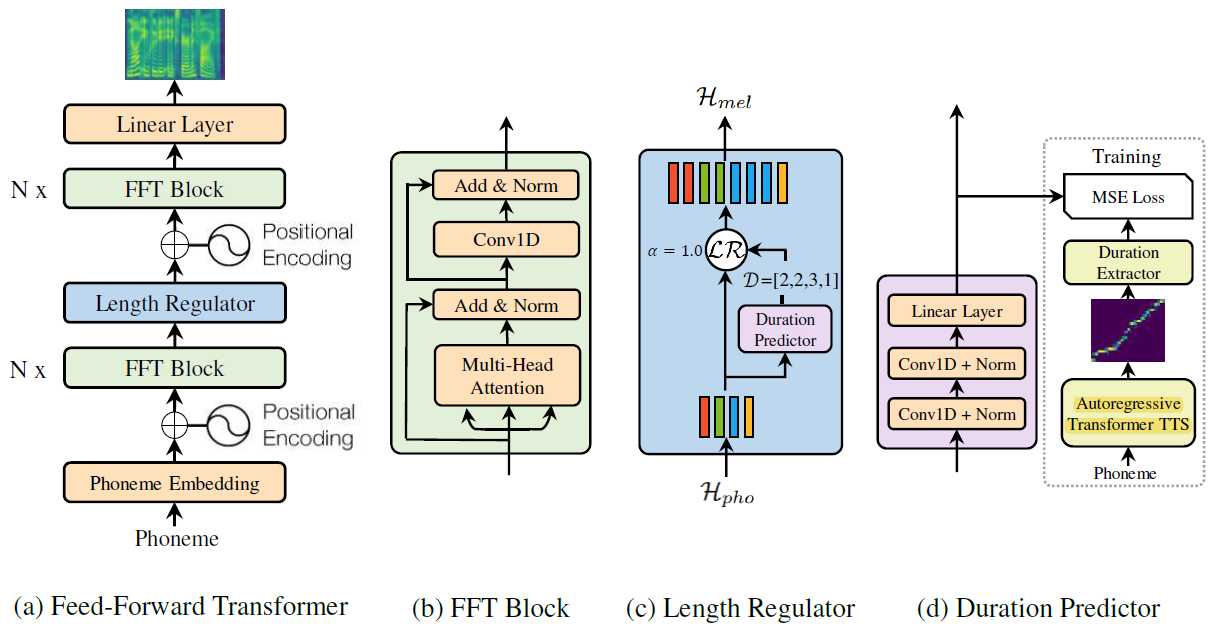
Feed-Forward Transformer를 활용한 non autoregressive 모델로 위 그림처럼 구성되어 있으며 과정은 다음과 같다.
1) Phoneme을 입력으로 받아 가장 먼저 embedding을 진행하고, 이후 Transformer의 attention에서 활용하기 위해 positional encoding을 수행하여 위치 값을 추가한다.
2) Encoding된 값이 Feed-forward Transformer를 지난다.
3) Phoneme 길이가 mel-spectrogram 시퀀스와 다른 경우 이를 해결하기 위해 Length Regulator를 사용하여 phoneme 시퀀스를 mel-spectrogram 시퀀스와 일치시킨다.
4) 다시 한번 Feed-Forward Transformer를 위해 positioning encoding을 수행한다.
5) 마지막으로 linear layer로 384 dim을 80 dim으로 변환하여 mel을 출력한다.
Feed-forward Transformer

Long-term dependency 문제를 해결하기 위해 recurrence 대신 attention만을 사용해 input과 output의 dependency를 찾아낸 모델이다.
- Transformer에서 encoder에 해당하는 self-attention을 채택하여 활용한 것으로, Multi-Head Attention과 Conv1D를 갖는 FFT block을 채택했다.
- 여러 개의 block은 phoneme을 mel-spectrogram으로 변환한다. phoneme과 mel-spectrogram에 각각 N개의 block을 갖고 있고, 그 사이에 length regulator를 두어 phoneme과 mel-spectrogram 사이의 길이가 다른 것을 해결했다.
- 2개의 1D Conv layer는 ReLU와 함께 사용하고, multi-head attention은 cross-position 정보를 추출하기 위해 사용된다.
- 인접한 hidden state가 phoneme와 mel-spectrogram에서 더 가까운 관계를 갖는 이론 때문에 시도하게 되었다고 한다.
- 그리고 사진을 보다시피 residual connection을 사용한 모습을 표현한 화살표와 ADD, layer normalization을 사용한 모습을 확인할 수 있다.
Length Regulator

FFT에서 phoneme과 mel-spectrogram 간의 mismatch 해결하기 위해 제안되었으며, 덕분에 음성 속도와 운율 조절이 가능하게 만들었다.
- Phoneme이 mel-spectrogram보다 대체로 작은데, phoneme duration d를 이용해, length regulator로 phoneme의 hidden state를 d번 확장하여 일치시킨다. (H_pho – phoneme 시퀀스, D – duration 시퀀스) α는 하이퍼파라미터: 시퀀스의 길이를 확장하는 역할로 음성의 속도 결정
- 알파가 1일 경우, 기본 값인 D=[2,2,3,1]이 출력으로 나오고, 1.3일 경우 D=[2.6,2.6,3.9,1.3]이 되어 반올림을 이용해 D=[3,3,4,1]과 같은 duration 시퀀스가 출력된다.
- 그럼 H_mel은 D의 개수에 따라 H_mel=[h1,h1,h1/h2,h2,h2/h3,h3,h3,h3/h4]와 같이 구성된다. 이 원리를 활용해 단어 사이에 길이를 마음대로 다룰 수 있다.
Duration Predictor
ReLU를 사용하는 1D Conv 2개와 linear layer를 통해 output으로 scalar 결과를 출력한다.
- Ground truth를 도입할 때, autoregressive transformer TTS를 사용하여, phoneme을 넘겨서 받은 attention을 이용해 phoneme의 duration을 예측해낼 수 있다.
- 추정한 duration을 GT로 넘겨서 phoneme에서 같은 duration을 내어 mel loss로 학습한다.


Result
Dataset

정확도를 측정하기 위해 LJSpeech를 활용했다. 13100개 데이터(24시간)를 갖고 있다. 300개 는 테스트로 활용하고, 나머지는 학습에 활용한다.
성능 확인을 위해 MOS로 측정했으며, 비교 대상으로 Tacotron2와 Transformer TTS를 두고 vocoder는 Waveglow를 선택했다. 그 결과 Tacotron이 3.86, Transformer TTS가 3.88을 기록했고 FastSpeech는 3.84로 오차범위로 비슷한 성능을 확인할 수 있다.
Synthesize Speed

- FastSpeech의 핵심은 비슷한 성능이지만 Non Autoregressive 모델로 inference 속도가 빠르다는 점이다. 같은 문장을 합성할 때 Acoustic Model 기준 Transformer TTS는 6.7초가 걸린 것과 비교해 0.025초밖에 소요되지 않았다. Vocoder를 감안하더라도 확실한 차이를 보이는 것을 확인할 수 있다.
Robustness

- Attention alignment를 확실하게 잡는지 여부도 FastSpeech의 중요한 요소다. 이를 위해 50개의 문장을 생성하여 중복해서 발음하거나 무시하는 경우가 Tacotron2와 Transformer TTS는 각각 24%, 34% 비율로 발생했지만, FastSpeech는 전혀 문제가 발생하지 않았다.
Length Control

- Phoneme duration을 조절하여 mel-spectrogram의 길이를 조절할 수 있다. 1배속과 차이 없이 부드럽게 0.5배속과 1.5배속에서도 안정적으로 합성해낼 수 있다. 또한 공백에 duration을 늘려 단어 사이에 쉬는 공간을 둘 수 있다. 이는 운율 성능의 향상으로 이어지게 된다.
Conclusion
FastSpeech는 이전의 모델들과 비슷한 품질을 보이지만, 차원이 다르게 빠른 합성 속도를 보인다. 또한 발음이 씹히거나 반복되는 문제를 완벽히 해결했고 속도 조절도 유연하게 가능하다.
- 다음 목표는 기존에 3.8로 기록된 성능을 최대한 끌어올리고, multi-speaker를 적용하고자 한다. 또한 FastSpeech와 Vocoder를 함께 학습해 완전한 end-to-end를 구현하고자 계획한다.
- 그리고 바로 1년 뒤 FastSpeech2에서 Teacher model을 완전히 배제시키고, 성능도 MOS 4점대로 향상시켰다. 또한 위에서 언급한 end-to-end 구조의 합성 모델인 FastSpeech2s를 제안했다. 자세한 내용은 다음 포스팅인 FastSpeech2에서 다루고자 한다.